sentiment_analysis_glassdoor
Sentiment Analysis of Data Science Job Reviews on Glassdoor
Project Overview
This project involves web scraping Glassdoor reviews for data science job postings to analyze sentiment and explore how review ratings correlate with textual sentiment. The goal is to understand how employees describe their experiences and whether sentiment aligns with the number of stars given.
📖 Read the full article on medium.com.
Table of Contents
Web Scrapping Glassdoor Data
Since Glassdoor lacks a public API, I used Selenium and BeautifulSoup to extract job listings and reviews. However, scraping was limited due to a 403 Forbidden error after a small number of requests.
Example Scraping Function:
def get_page(url, headers):
"""Fetch webpage content using BeautifulSoup."""
try:
req = Request(url, headers=headers)
page = urlopen(req)
soup = BeautifulSoup(page, "html.parser")
return soup
except HTTPError as e:
print(f"Error opening page {e}")
Text Preprocessing
In order to proceed with sentiment analysis, I had to perform text preprocessing which involved the below. When working on NLP projects, I am usually a big fan of the NLTK library, but this time I wanted to try out TextBlob.
- Removed punctuation, numbers, and stopwords
- Tokenized text using TextBlob instead of NLTK
Example of cleaning reviews:
# assign new clean review column
df = df.assign(clean_review = df.reviews.map(lambda x: ' '.join(TextBlob(str(x)).words)))
Data Exploration & Visualization
Once the data is cleaned I can finally move on to the fun part, visualizations! I created a word cloud from the most frequent words in the reviews:

Top words included good, work, people, great, benefits, culture, balance, pay, management, life, reflecting common themes in workplace discussions.
Sentiment Analysis
TextBlob Sentiment Analysis
TextBlob measures:
- Polarity (-1 to 1): Negative to positive sentiment
- Subjectivity (0 to 1): Objective to subjective content
Here is an example:
sample_review = df['clean_review'].iloc[0]
TextBlob(sample_review).sentiment
Observations:
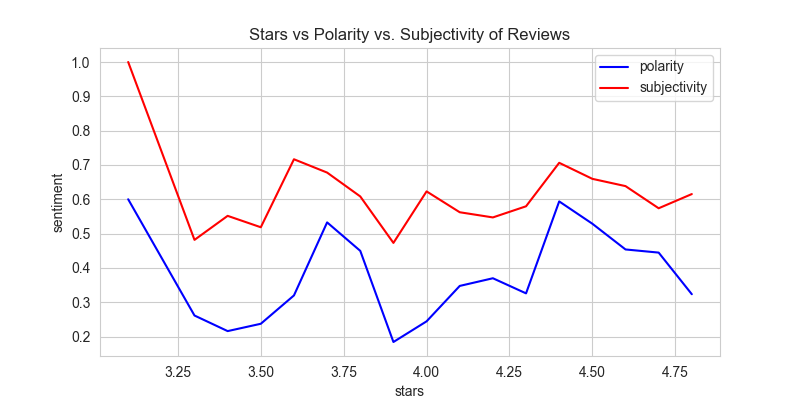
- Higher-rated companies didn’t always have higher polarity scores.
- Some lower-rated reviews had neutral or even positive sentiment.
VADER Sentiment Analysis
VADER provides:
- Positive, Neutral, Negative scores
- Compound score (-1 to 1), summarizing overall sentiment
Here is an example:
sid = SentimentIntensityAnalyzer()
sid.polarity_scores(sample_review)
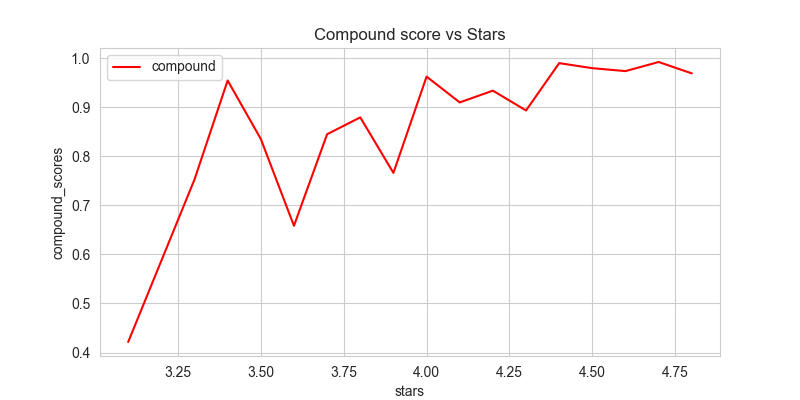
Sentiment vs. Star Ratings
While VADER’s compound scores showed a clearer relationship with ratings, inconsistencies still emerged.
Polarity vs. Stars
VADER Compound Scores
Conclusion
While sentiment analysis provides valuable insights, review ratings don’t always align with textual sentiment. This raises questions about how employees rate companies and whether numerical ratings alone reflect job satisfaction.