Lead Conversion Prediction
Project Overview
The goal of this project is to predict whether a lead will convert into an opportunity or not.
Data Processing and Cleaning
Data was collected from the Lead table in SalesForce MSSQL server by connecting to the database using pymssql and querying the data table. There were about 52000 total rows and 44 columns. Some of the lead data collected included First Name, Last Name, Title, Email, Country, Company size, Industry, Phone, Website, Created Date, Lead Source and Lead Owner.
Data cleaning involved grouping industries together, assiging a title score, changing data types, mapping the number of employees to categorical values, removing columns with too many missing values, and adding fiscal quarters based on created date.
Data Exploration & Visualization
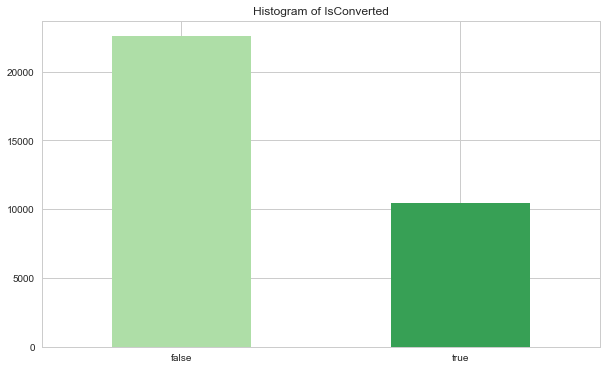
Plotting the target variables made it clear that there are more unconverted leads than converted leads.
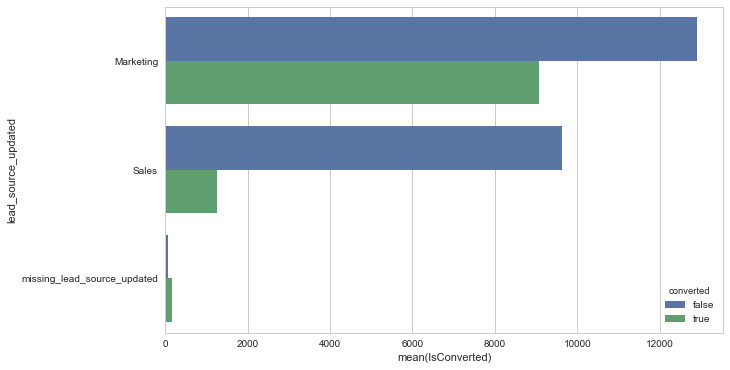
In looking at the lead source, we can see that Marketing generates more leads, and a higher percentage of Marketing leads convert, whereas there are fewer converted Sales sourced leads.
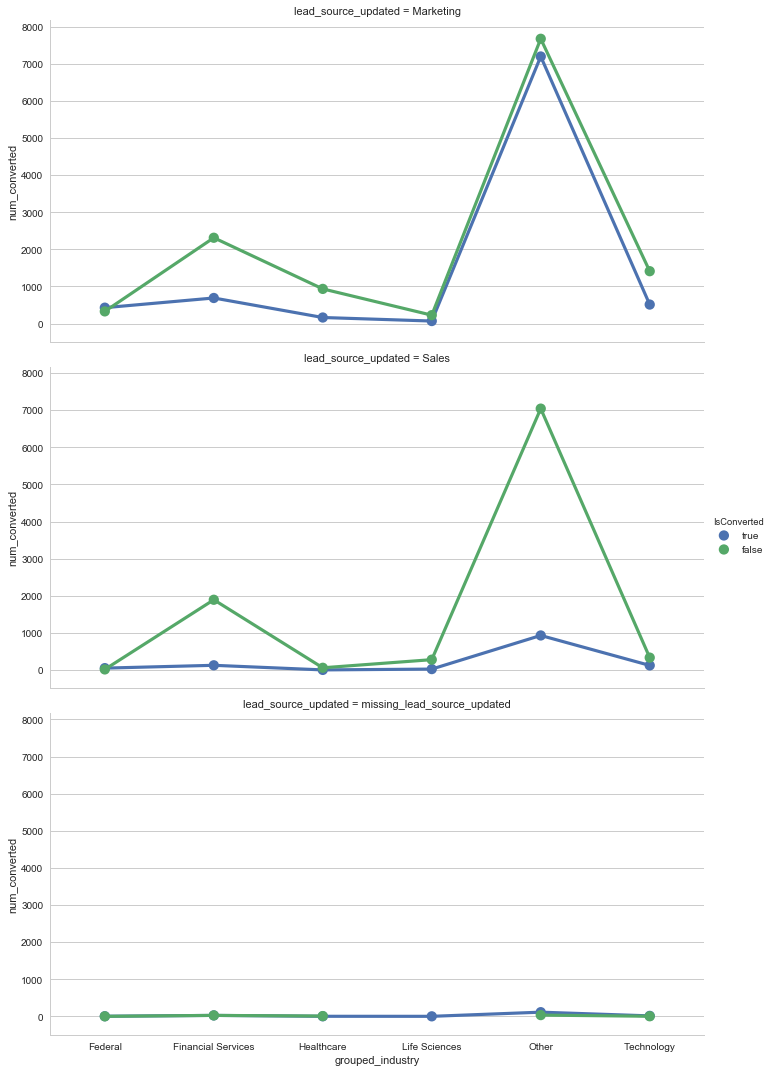
When digging deeper and considering industry and source, we can see that Marketing leads with ‘Other’ industry tend to convert despite not being in one of the dominant industries whereas Sales ‘Other’ lead dont quite convert as much. This looks like it can be attributed to a data quality issue and not that we dont necessarily know the lead industry. Lastly, I noticed that company size seems to have a larger impact on Sales leads converting than on Marketing leads.
Machine Learning models: Decision Tree, Random Forest and Logistic Regression
Decision Tree
I split the data into training and test sets using 85% of the data for model training and 15% for model evaluation. I chose to start by using a decision tree model because it is easy to interpret. As a first pass, I explored feature importance without doing much parameter tuning, but instead initially set the maximum tree depth to 5 because I didn’t want to build a very deep tree and overfit the training data. And, I chose to set the minimum sample split to 10 (there needs to be a minimum of 10 observations for there to be a split on a node).
X, y = shuffle(df_transformed, df_us.IsConverted_2 , random_state=23)
'''
FEATURE IMPORTANCE USING DECISION TREE
'''
# split data into training and test sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.15, random_state=1)
# create decision tree model and fit to training data set to obtain feature importance
tree_model = tree.DecisionTreeClassifier(criterion='gini', max_depth=5, min_samples_split=10,min_samples_leaf=5)
#tree_model = tree.DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
# predict test
tree_predicted = tree_model.predict(X_test)
In looking at the feature importance, the initial tree indicated that title score, lead source, marketing score, and owner were among the important features.
| Feature Importance | Feature |
|---|---|
| 0.931174 | Title Score |
| 0.027602 | LeadSource |
| 0.013535 | Marketing Score |
| 0.007659 | Source |
| 0.007086 | OwnerId |
| 0.004813 | Type |
| 0.003364 | Owner |
Next, I used GridSearchCV to perform cross validation to do parameter tuning, to search for best tree depth and minimum sample split. The default cross validation sets k to 3, found minimum samples per split to be 5 and max depth of 3, and the best score was 82%.
'''
Cross validation using Grid Search - for best parameters
'''
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':range(3,20), 'min_samples_split':range(5, 20), 'min_samples_leaf':range(5,15) }
clf = GridSearchCV(tree.DecisionTreeClassifier(), parameters, n_jobs=4)
clf.fit(X=x, y=y)
tree_model = clf.best_estimator_
print (clf.best_score_, clf.best_params_)
(0.82215029041626331, {‘min_samples_split’: 5, ‘max_depth’: 3, ‘min_samples_leaf’: 5})
The features with highest feature importance were:
| Feature Importance | Feature |
|---|---|
| 0.956501 | Title Score |
| 0.028352 | LeadSource |
| 0.007278 | OwnerID |
'''
FEATURE IMPORTANCE USING DECISION TREE
'''
X, y = shuffle(df_transformed, df_us.IsConverted_2 , random_state=23)
# split data into training and test sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.20, random_state=1)
# create decision tree model and fit to training data set to obtain feature importance
tree_model = tree.DecisionTreeClassifier(max_depth = clf.best_params_['max_depth'],
min_samples_split = clf.best_params_['min_samples_split'],
min_samples_leaf= clf.best_params_['min_samples_leaf'])
#tree_model = tree.DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
# predict test
tree_predicted = tree_model.predict(X_test)
After training the model with the best parameters, the model scored 93% on the test set.
# Decision Tree performance
print "Decision Tree score is: ", tree_model.score(X_test, y_test)
# Classification Report
print "\nClassification Report:\n"
print (classification_report(y_test, tree_predicted))
# Confustion Matrix
print "Confusion Matrix:"
print(get_confusion_matrix(y_test, tree_predicted))
print confusion_matrix(y_true=y_test,y_pred=tree_predicted)
Decision Tree score is: 0.931034482759
Classification Report:
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.92 | 0.98 | 0.95 | 3365 |
| 1 | 0.95 | 0.83 | 0.89 | 1594 |
| avg/total | 0.93 | 0.93 | 0.93 | 4959 |
Confusion Matrix:
| NotConverted-Predicted | Converted-Predicted | |
|---|---|---|
| NotConverted-Actual | 3297 | 68 |
| Converted-Actual | 274 | 1320 |
In comparison to the Random Forest and Logistic Regression, the tuned Decision Tree performed the worse.
Random Forest
Using 80% training and 20% test set and 1500 estimators, the Random Forest model scored 98.6% accuracy
'''
Random Forest Classifier
'''
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.20, random_state=1)
rf = RandomForestClassifier(n_estimators = 1500)
rf.fit(X_train, y_train)
rf_predicted = rf.predict(X_test)
# Random Forest performance
print "Random Forest score is: ", rf.score(X_test, y_test)
# Classification Report
print "\nClassification Report:\n"
print (classification_report(y_test, rf_predicted))
# Confustion Matrix
print "Confusion Matrix:"
print(get_confusion_matrix(y_test, rf_predicted))
Random Forest score is: 0.986988847584
Classification Report:
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.99 | 0.99 | 0.99 | 4401 |
| 1 | 0.99 | 0.97 | 0.98 | 2055 |
| avg/total | 0.99 | 0.99 | 0.99 | 6456 |
Confusion Matrix:
| NotConverted-Predicted | Converted-Predicted | |
|---|---|---|
| NotConverted-Actual | 4378 | 23 |
| Converted-Actual | 61 | 1994 |
Logistic Regression
Using 80% training and 20% test set, the Logistic Regression model scored 97.3% accuracy
'''
Logistic Regression
'''
# training and testing
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2, random_state=1)
logreg = LogisticRegression(random_state=123, verbose=1)
#Cs = np.logspace(-7, 5, num=15)
logreg = LogisticRegression(C=10.0)
logreg.fit(X_train,y_train)
logreg_predicted = logreg.predict(X_test)
# Logistic Regression performance
print "\nC is ", c, "Logistic Regression score is: ", logreg.score(X_test, y_test)
# Classification Report
print "\nClassification Report:\n"
print (classification_report(y_test, logreg_predicted))
# Confustion Matrix
print "Confusion Matrix:"
print(get_confusion_matrix(y_test, logreg_predicted))
C is 100000.0 Logistic Regression score is: 0.972893432466
Classification Report:
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.98 | 0.99 | 0.98 | 4432 |
| 1 | 0.97 | 0.95 | 0.96 | 2024 |
| avg/total | 0.97 | 0.97 | 0.97 | 6456 |
Confusion Matrix:
| NotConverted-Predicted | Converted-Predicted | |
|---|---|---|
| NotConverted-Actual | 4368 | 64 |
| Converted-Actual | 111 | 1913 |
Conclusion - Model Summary
While the tuned Decision Tree attributed more information gain to fewer features, the score was 93% and underperformed in comparison to the average scores of Random Forest (98.7%) and Logistic Regression (97.3%). Random Forests beat Logistic Regression by quite a bit, so I think this is the model we should implement for predicting whether a lead will convert to an opportunity or not.